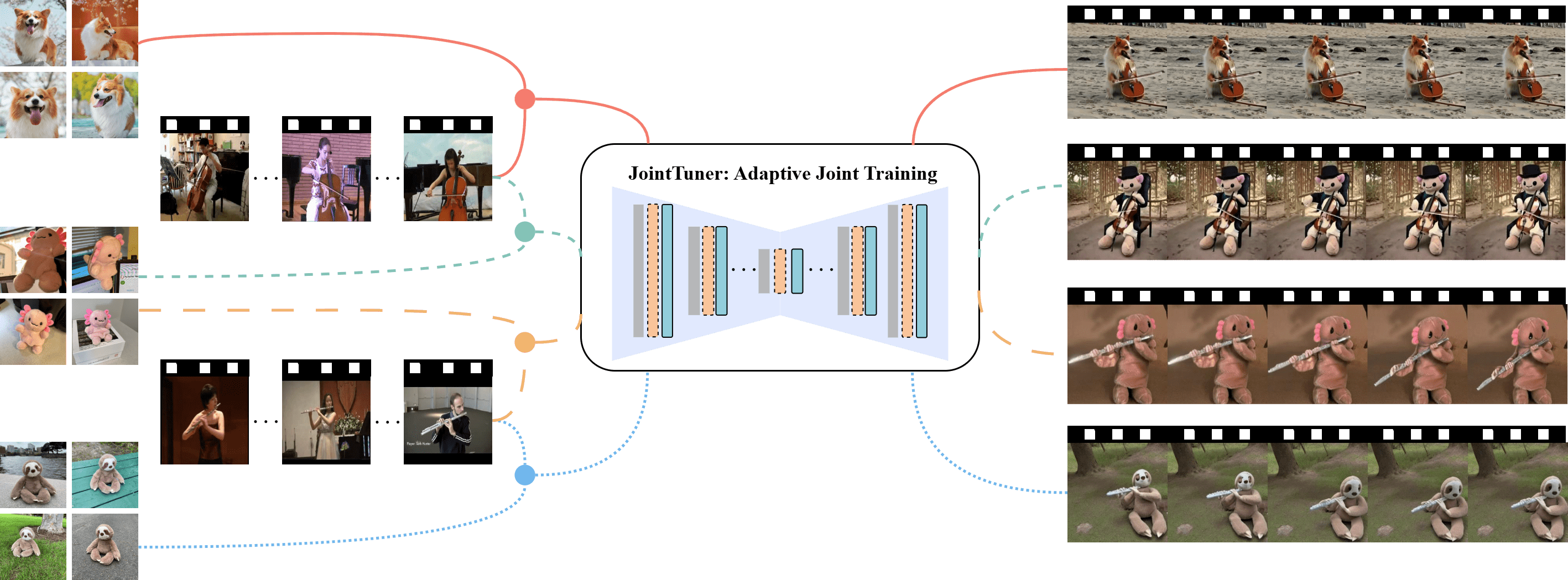
Recent advancements in customized video generation have significantly improved the adaptation of appearance and motion. However, traditional approaches often decouple appearance and motion training, leading to concept interference and inaccurate feature rendering. Furthermore, these methods frequently suffer from appearance contamination, where background and foreground elements from reference videos distort the generated output. To tackle these limitations, we propose JointTuner, designed to jointly optimize appearance and motion dynamics. We introduce two key innovations: Gated Low-Rank Adaptation (GLoRA) and Appearance-independent Temporal Loss (AiT Loss). GLoRA employs a context-aware activation layer to dynamically steer LoRA modules toward optimizing either appearance or motion while preserving spatio-temporal consistency. Concurrently, the AiT Loss leverages channel-temporal shift noise to isolate motion-related high-frequency signals, forcing the model to prioritize motion learning without compromising appearance. JointTuner is architecture-agnostic, supporting both UNet and Diffusion Transformer backbones like CogVideo and Wan2.1. We also establish a systematic evaluation framework covering 90 scenarios, demonstrating superior performance in semantic alignment, motion dynamism, temporal consistency, and perceptual quality.
Architecture of JointTuner, an adaptive joint training framework featuring two primary steps:(1) integrating GLoRA into Transformer blocks for efficient fine-tuning, and (2) optimizing GLoRA via two complementary losses. The original diffusion loss utilizes reference images to preserve appearance details, while the AiT Loss leverages reference videos to focus on motion patterns. The pre-trained text-to-video model remains frozen, with only GLoRA parameters updated during training. During inference, trained GLoRA weights are loaded to generate customized videos conditioned on the input prompt.



A dog*.



A wolf plushie*.
A person playing the flute*.
A curious dog* playing a wooden flute* in the heart of a lush, green jungle...
A whimsical wolf plushie* playing a wooden flute* on a misty cobblestone street...
A person playing the cello*.
A golden dog* playing the cello* in a peaceful snowy meadow...
A whimsical wolf plushie* playing the cello* on a serene beach...



A bear plushie*.



A terracotta warrior*.
A person playing the flute*.
A whimsical bear plushie* playing the flute* amidst a serene snowy landscape...
A terracotta warrior* playing the flute* on a tranquil beach...
A person playing the cello*.
A whimsical bear plushie* playing the cello* in a serene snowy landscape...
A terracotta warrior* playing a weathered cello* on a quiet cobblestone street...



A cat*.



A pink plushie*.
A person playing the flute*.
A curious cat* playing a wooden flute* perched on a mossy tree stump...
A whimsical pink plushie* playing a delicate flute* in a serene snowy landscape...
A person playing the cello*.
A curious cat* playing the cello* on a lush green meadow...
A pink plushie* playing the cello* seated in the snow...
A whimsical bear plushie* playing the cello* on a sunlit meadow, surrounded by gently swaying wildflowers and bathed in golden afternoon light.

Input: Appearance + Motion
DualReal (on CogVideo-5B)
JointTuner (on CogVideo-5B)
LoRA (on Wan2.1-1.3B)
JointTuner (on Wan2.1-1.3B)
A vintage clock* driving* through a snowy landscape, its hands frozen in time as it appears to drive across a serene, wintery countryside.

Input: Appearance + Motion
DualReal (on CogVideo-5B)
JointTuner (on CogVideo-5B)
LoRA (on Wan2.1-1.3B)
JointTuner (on Wan2.1-1.3B)
A whimsical wolf plushie* playing the cello* in a snowy forest clearing, surrounded by towering pines dusted with fresh powder, under a pale winter sky.

Input: Appearance + Motion
DualReal (on CogVideo-5B)
JointTuner (on CogVideo-5B)
LoRA (on Wan2.1-1.3B)
JointTuner (on Wan2.1-1.3B)
A bear plushie*.
A dancer twirling* in a hay bale.
A bear plushie* twirling* in the snow.
A cat*.
A mallard walking* in the grass near a river.
A cat* walking* in the snow.

A backpack*.
A train turning* on a train track.
A backpack* turning* in the snow.

A monster toy*.
A person lifting a barbell*.
A monster toy* lifting a barbell* in the snow.
@article{chen2025jointtuner,
title={JointTuner: Appearance-Motion Adaptive Joint Training for Customized Video Generation},
author={Fangda Chen and Shanshan Zhao and Chuanfu Xu and Long Lan},
journal={arXiv preprint arXiv:2503.23951},
year={2025}
}